Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Dynatrace Community
- Dynatrace
- Ask
- Open Q&A
- Custom problem intergration
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
10 Mar 2019
03:25 PM
- last edited on
13 Dec 2021
11:18 AM
by
![]() MaciejNeumann
MaciejNeumann
Hello,
When using the custom problem integration, I notice that by design, {Tags} and {ImpactedEntities} are not JSON but very inconsistant CSV is used instead. This means that any JSON parser stops at this point and you have to parse the rest on your own.
You get keys, keys with values and keys starting with [] all seperated by ",".
My intention would be to convert from CSV to records, and then splitup by ":" finding my key and returning the value that it contains.
Nicer would be that dynatrace would send all JSON, just add a dummy value to keys without value and do not use the []. characters, and ofcourse put {} around the CSV.
Does anybody have any thoughts about this?
KR Henk
Solved! Go to Solution.
Labels:
- Labels:
-
problem detection
-
tagging
6 REPLIES 6
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
11 Mar 2019 08:24 AM
With the tags - you are right, it's not a structure, but a string of tags separated by a comma.
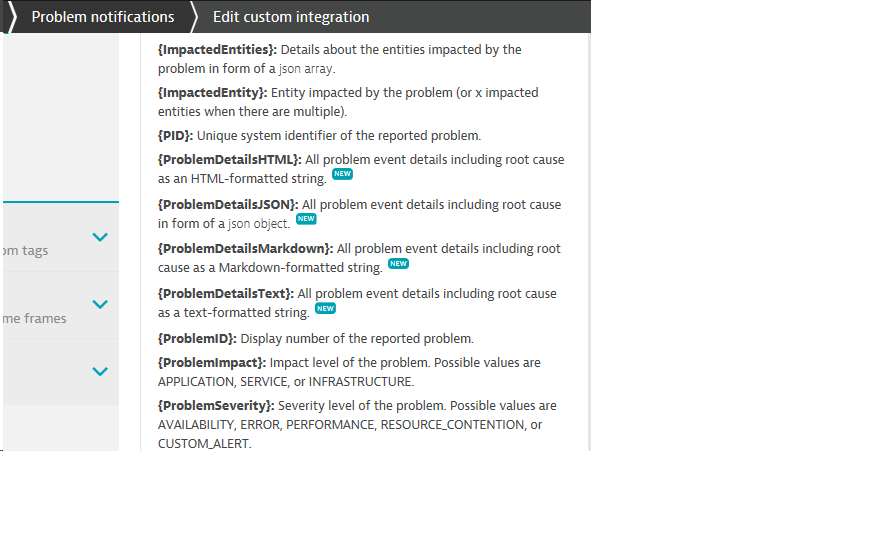
However, the ImpactedEntities is an array of JSON objects thus you don't have do any special handling.
With tags - They are accessible in a structured way in the {ProblemDetailsJSON} placeholder in "tagsOfAffectedEntities" attribute.
Certified Dynatrace Master | Alanata a.s., Slovakia, Dynatrace Master Partner
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
11 Mar 2019 09:20 AM
Hi Július,
Great answer thanks, now I see the difference between ImpactedEntity and ImpactedEntities
And I norice the "new" in my 162 instance(-;
KR Henk
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
11 Mar 2019 09:35 AM
These "New" placeholders are there for quite a long time - from Dynatrace 1.143.
Certified Dynatrace Master | Alanata a.s., Slovakia, Dynatrace Master Partner
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
11 Mar 2019 10:38 AM
Then this is strange (-;
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
11 Mar 2019 11:16 AM
Yes, it shows them as new - but there are "new" for about 10 months. 10 months is a very long time for Dynatrace 🙂
See more in this blog post.
Certified Dynatrace Master | Alanata a.s., Slovakia, Dynatrace Master Partner
