This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Looking to upgrade from Dynatrace Managed to SaaS?
See how
- Dynatrace Community
- Dynatrace Managed
- Dynatrace Managed Q&A
- Cassandra service unable to start due to commit log corruption
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
17 Sep 2020
04:05 AM
- last edited on
19 Jun 2023
09:56 AM
by
![]() Karolina_Linda
Karolina_Linda
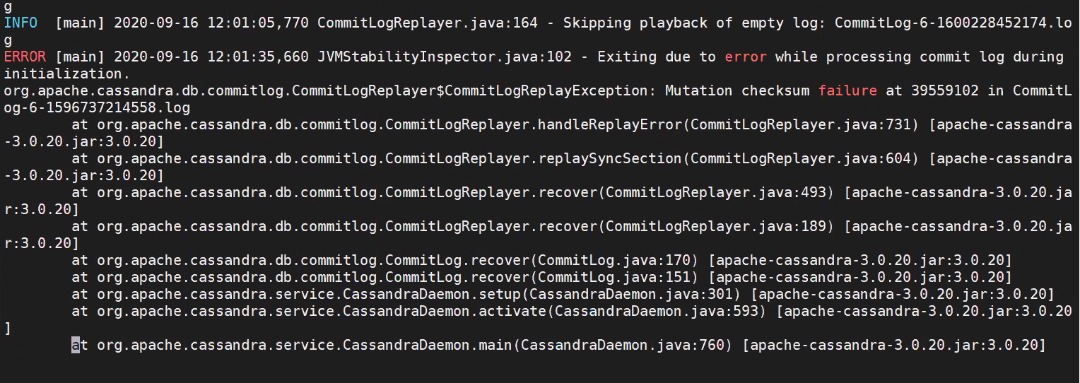
When a Dynatrace Managed server is restarted ungracefully, there is a high chance that Dynatrace Managed server fails to start up again due to corrupted Cassandra commit log. The quick fix is to delete the offending commit log before starting up Dynatrace Managed service again.
Could there be a way to make Cassandra more resilient to unexpected shut downs? Or automatically delete the offending commit log and move on?
Not that unexpected shut down happens frequently but when it happens, monitoring downtime is stays even longer until someone manually removes the corrupted commit log.
Solved! Go to Solution.
Labels:
- Labels:
-
cassandra
-
dynatrace managed
Reply
3 REPLIES 3
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
17 Sep 2020 11:54 AM
The machine must have been hard-stopped in the middle of Cassandra writing a commit log onto disk. That's a known issue that we'll fix in a future release. No ETA yet.
Senior Product Manager,
Dynatrace Managed expert
Dynatrace Managed expert
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
18 Nov 2021 02:06 PM
Radek, anything new for this issue? I've just found the same problem on one Managed environment.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
18 Nov 2022 07:15 AM
Yes, in Dynatrace Managed version 1.210 we've set the Cassandra JVM option "Dcassandra.commitlog.ignorereplayerrors=true"
This ignores the replay of any corrupted commit logs and will allow you to restart the node without having to identify each individual corrupt commit log and having to move out/delete if there are a large number of corrupt commit logs.
Senior Product Manager,
Dynatrace Managed expert
Dynatrace Managed expert
Reply
