This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Alerting
Questions about alerting and problem detection in Dynatrace.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Alerting
- Setup custom alert for all services
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
11 Oct 2018 09:24 PM
Is there a way to setup custom alerts for all services. I found that its possible to setup a custom alert for 'All Hosts'. Could not see a way to do this for 'All services'. Is there a way to do this?
Solved! Go to Solution.
Labels:
- Labels:
-
problems classic
7 REPLIES 7
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
12 Oct 2018 07:44 AM
Hi,
We did have that some time ago but we did remove the 'All' option. Its a very dangerous setting in large environments.
Also the benefit is not really clear as those services are completely different in terms of response times and error rates and an 'all' threshold in most cases does not make much sense.
What would you like to do?
Best regards,
Wolfgang
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
12 Oct 2018 04:00 PM
What I wanted to do was to just have a notification sent anytime an error (HTTP / Server side error) was detected for any service. As you said above it probably would not make sense to have such an alert in large environments. In our case, it's nice to have an alert that an error was detected on a service / multiple services.
Similarly it would have been nice to have a general error metric that stands for any kind of error. Users can choose this if they want to track all errors (instead of having four categories such as Client side, Server side, HTTP 4xx, HTTP 5xx). So, basically it could easily cover the use case "For any error detected on any service let me know". Based on your answer, I think my only option is to set it up manually for each service.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
15 Oct 2018 07:21 AM
Yes at the moment you have to be more specific and set it either on service level or on key transaction level.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
12 Feb 2019 01:54 PM
Hi all!
The thing is client got alert after 9 minutes when one process got connectivity rate 0%. Problem here that ops team were notified than something isn't working by managers before Dynatrace did it. I know we have sliding 5 and 15 minutes interval, but maybe there is an option to get notification much faster.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
12 Feb 2019 02:59 PM
@Vlad S. Why did'nt you got a much faster service related alert? We are alerting not necessarily on 5 min delay, if your service has high traffic and you get an increased error rate you will receive the alert within a minute instead of 5 minutes.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
12 Feb 2019 03:06 PM
My observation is 9 minutes delay almost on each Problem. Failure rate, decrease connectivity rate etc.
9 minutes for Slack alerting, Dynatrace MobileApp notification and even Problem popup in Dynatrace UI
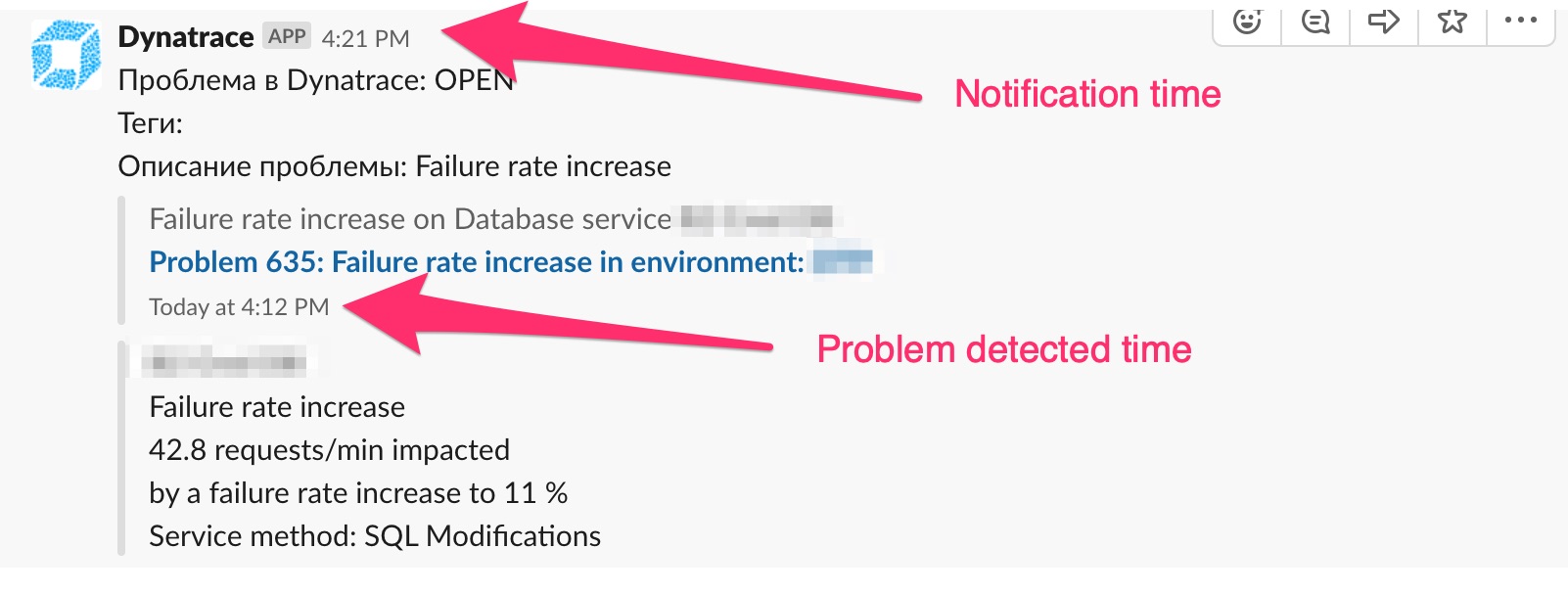
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
14 Feb 2019 03:25 PM
Hi again. WIth more higher load I see 11 minutes delay with the notification. Should I open support ticket or it can be tuned somehow?
Featured Posts
