This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Alerting
Questions about alerting and problem detection in Dynatrace.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Alerting
- Alerts after a maintenance window
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
19 Feb 2019 12:41 AM
Hello,
We would like to know how everyone is handling Alerts/Notification after a maintenance window.
To be more specific, here is our situation - We have a standard maintenance window where any events triggered during this period would be suppressed. Once the window is ended, our current monitoring system scans and sends out notification of system that is not available. My understanding is that in AppMon we don’t have this option and wondering how would it work in Dynatrace Managed. Can anyone share your experience and any suggestion is greatly appreciated.
Thanks
Raj. C
Thanks in advance, Raj
Solved! Go to Solution.
Labels:
Reply
19 REPLIES 19
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Sep 2019 06:43 AM
Hi guys anyone can spill some light on this?
If we have a maintenance window from 1:00 till 5:00 that say don’t send alerts on this period of time and there is problem open at 4:45 and it last for an hour will there be alert fired for this problem when the maintenance window will be close? And if so when this alert will be fired?
Thanks in advance
Yos
dynatrace certificated professional - dynatrace master partner - Matrix Soft Ware Division - Israel
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Sep 2019 08:23 AM
Alert can be send if in alerting profile you have info to send alerts if problem is longer than xx minutes. Then it maybe send in condition you’ve provided. But I’ve never tested it, it is my assumption.
Sebastian
Regards, Sebastian
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Sep 2019 10:04 AM
Lets play
Alerting profile set to send immediate alert, and there is email notification that this alerting profile is attached to.
Problem start at 4:30 during maintenance window which is mark as not to send alerts.
At 5:00 the maintenance window close and problem is still on going.
Will alert be send at 5:00 ?
If the alerting profile is set to send alerts after 15 minutes from problem start, what will happen with above scenario ?
Yos
dynatrace certificated professional - dynatrace master partner - Matrix Soft Ware Division - Israel
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Sep 2019 02:21 PM
In general dynatrace is sending alerts on problem start r after configured amount of minutes. So if problem will have immediately alerts during maintenance window and problem will still be on after it there will be no alerts. What I’m thinking about is situation when problem will start during maintenance window and alerts are configured to be delayed. What if this alert trigger will be right after maintenance window, it can be send in my opinion.
Sebastian
Regards, Sebastian
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Sep 2019 12:10 PM
Hi Yos,
Within Dynatrace, notifications are usually sent on Problem OPEN and (optionally) on Problem CLOSE. With the maintenance window setup we have two options of suppression:
a) do not detect any Problems, or
b) keep detecting Problems but do not send out notifications.
In your scenario, where problematic behaviour starts during a maintenance window and it continues after the window finished, I will expect the following Dynatrace behaviour:
a) nothing will happen during the maintenance window. once the window closes, and Dynatrace starts detecting problems again, it will open a Problem, and the alert notification will trigger on Problem OPEN
b) during the maintenance window the Problem will OPEN, however alert notification is suppressed so no message is sent. Because the Problem is already OPEN, when the maintenance window closes I do not expect a notification to be sent because there is no Problem OPEN trigger happening again.
Best regards,
Radu
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Sep 2019 02:04 PM
Hן @Radu S.
Thanks for your answer.
Your expectations are as good as mine .... I do wonder what is the "official" answer here
Yos
dynatrace certificated professional - dynatrace master partner - Matrix Soft Ware Division - Israel
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
05 Jan 2020 05:15 PM
I'm looking into the same issue. I'm going to post and see if there has been any updates.
Right now... my thought is this..
I can create a maintenance window and set it to "detect but don't alert"
Once the window is over... I can use the API to pull for any "OPEN" alerts that meet specific tags
(We have particular processes tagged)
I scrape the information from the JSON file forthe problems i care about that are still OPEN and not CLOSED
I can then either
1) Take that information and send it to some 3rd party alerting system or
2) Send a CLOSE through the API on the problems i care about..
The idea being is that if the problem is closed... and the process is down.. a new alert will be triggered. (I need to test this and validate it with support. I'll also post here)
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
07 Jan 2020 02:33 PM
@Chris N. So as a managed customer we had the same question and this was our solution.
Once a month we would have patch night where the entire system would be taken down and systematically rebooted. So lets say that at 10pm, on January 19th till 5am January 20th, we will be restarting devices and we dont want to be alerted on issues as we are aware of them and performing reboots.
Set your maintenance window.
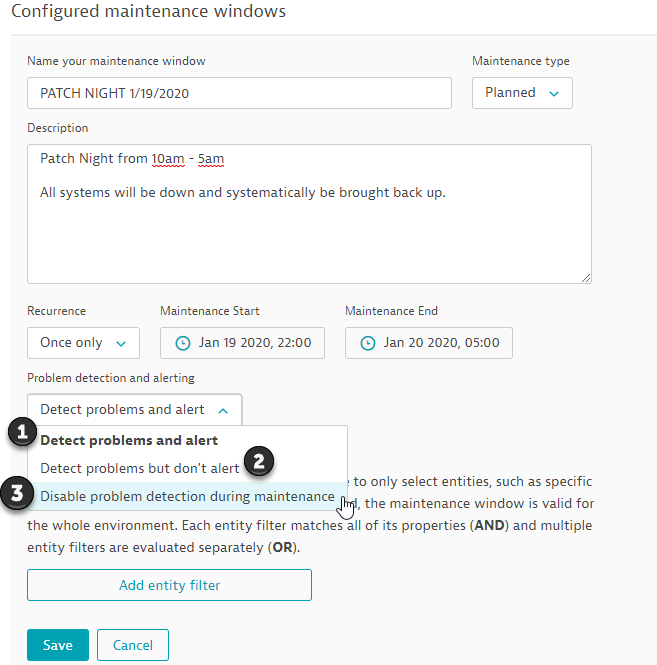 As you can see in the screen shot, we have named and filled out the details for the Patch night Maintenance. We defined the time frame and now we need to select the actions of alerts.
As you can see in the screen shot, we have named and filled out the details for the Patch night Maintenance. We defined the time frame and now we need to select the actions of alerts.
1.) Detect Problems and Alert - In this case all baseline and SLA calculation will be suspended for the duration of the maintenance window.
2.) Detect Problems but don't Alert - This is a viable option but has its drawbacks. The biggest issue with alerting users of issues after the maintenance window expires. Lets say Host A is the last server to reboot at patch night. Host A gets rebooted at 4;30am and has 30 mins to come up before that 5am maintenance window expiration. Lets say for some odd reason, that host does not come up, Its now 5:10am and the window has expired, Dynatrace will still list this host issue in the problems page but no alerts via email or custom integration will be generated as the problem opened up during that maintenance window when alerts were suppressed.
3.) Disable Problem Detection During Maintenance - This is what we use. Dynatrace will turn a blind eye on issues during the defined time frame. but most importantly, the system will then detect AND ALERT on any issues after the maintenance window expires. In this case, Host A would be alerted as unavailable after 'X' amount of time per your alert profile.
Keep in mind, I used hosts as an example but this goes for everything within Dynatrace so CPU, Memory, Disk Space, services, processes, transactions etc... Using the second option will not initiate alerts to problems that have opened up during the maintenance window, even if they remain open after the window expires.
Please let me know if you need anything.
-Chad
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
07 Jan 2020 03:20 PM
Regarding:
1.) Detect Problems and Alert - This really does nothing and totally negates the maintenance window as it will not suppress anything.
That is not quite true. In this case all baseline and SLA calculation will be suspended for the duration of the maintenance window (as with the other two options).
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Jan 2020 03:34 PM
Chad: Thanks for your insight on this matter. I have tested all 3 scenarios in maintenance window options and I have mostly encountered the same effects. 1) and 2) are spot on... that is what I see. 3) however.. I ran into a different outcome and I'm wondering if the results might need to be validated with a second test.
So in situation #3) I created a maintenance window. say one hour (use 8-9 am as an example)
The servers are bounced during this window.
The servers come up but the services of interest stay down
After the window expires.. .I still did not receive any alerts. In fact, what I saw was the services/processes of interest were showing green. It was as if a state change had not been checked after the maintenance window.
Is this what you encountered?
Now you did mention something in regards to the profile not alerting until after a specified period of time...
Are you indicating that within the alerting profile you change the value to something like:
"Send a notification if a problem remains open longer than 70 minutes" If I had a one hour maintenance?
SO in that instance..instead of one alerting profile you would have 2 ?
1 profile designed for maintenance windows where the "wait to alert until after the maintenance window length"
and
1 more profile with "normal wait times wanted when not in maintenance"
My only concern would be if this has the possibility to cause the second profile (normal wait times) to not stay in sync with the the actual state. Of course. "If that normal wait time " profile is out of sync (because it does not wait until the maintenance window is over) It would imply that it WILL be once the alert sent by the Maintenance profile is addressed and fixed?
What do you think?
-Chris
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Jan 2020 09:00 PM
Hey Chris,
So with our set up we have our processes alerting when any of them are not available via option 3. There are two hosts that serve up this process and are included within this process group. So when one goes down you don't get alerted as Dynatrace is thinking that the other process will take the load over. To correct this, we change the setting at the process group level.
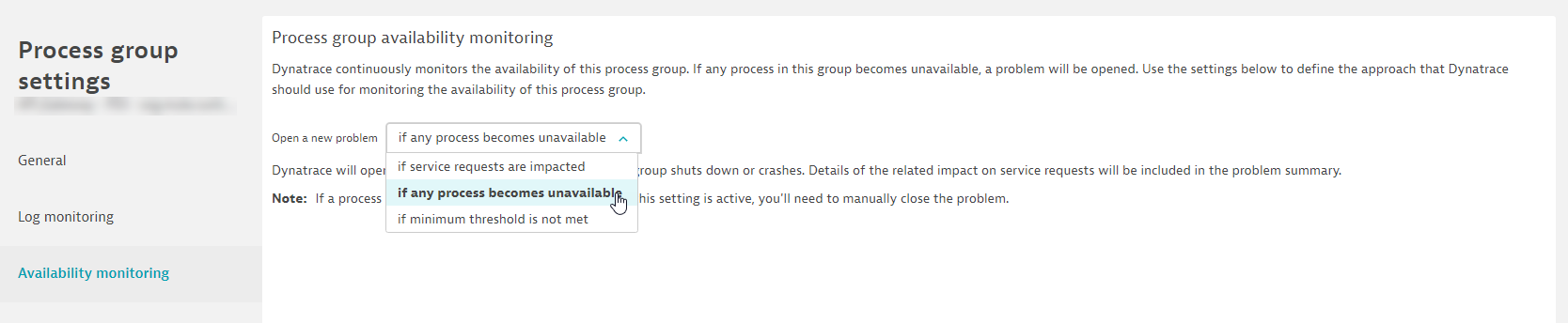
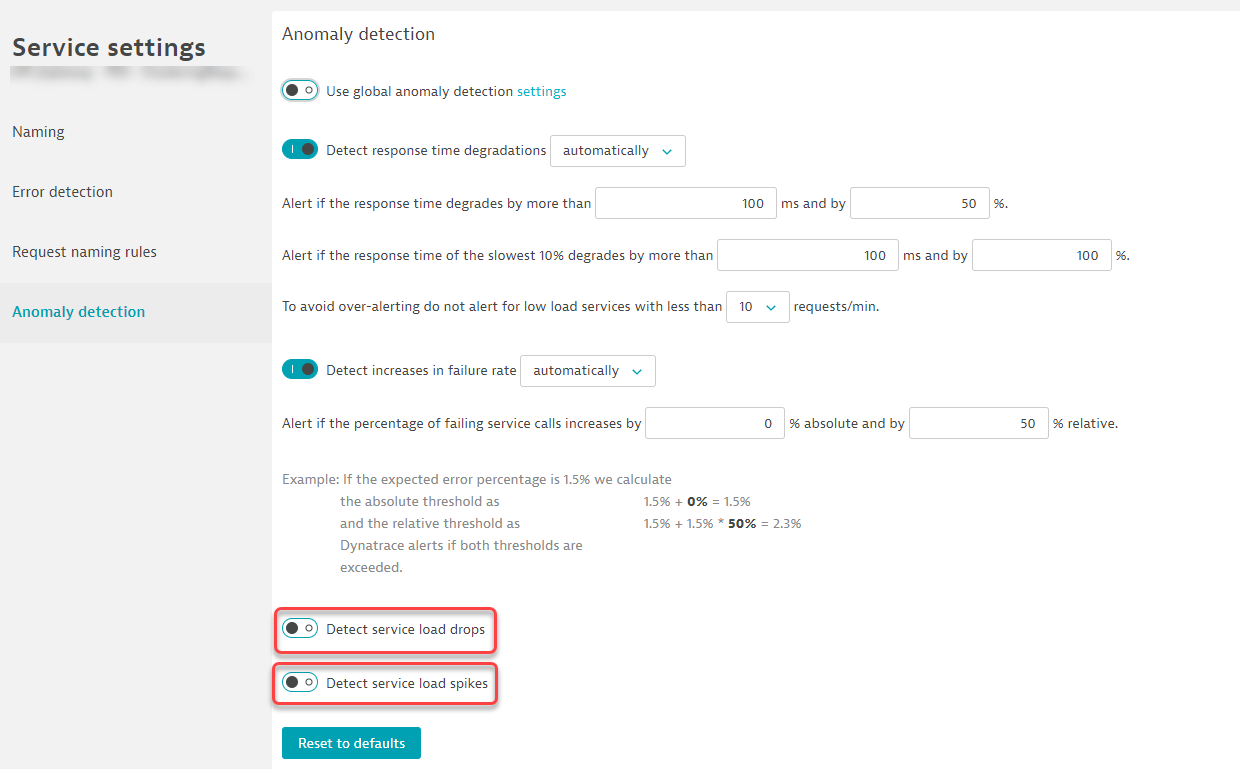
You can also configure the services to alert when the service load drops and or spikes:
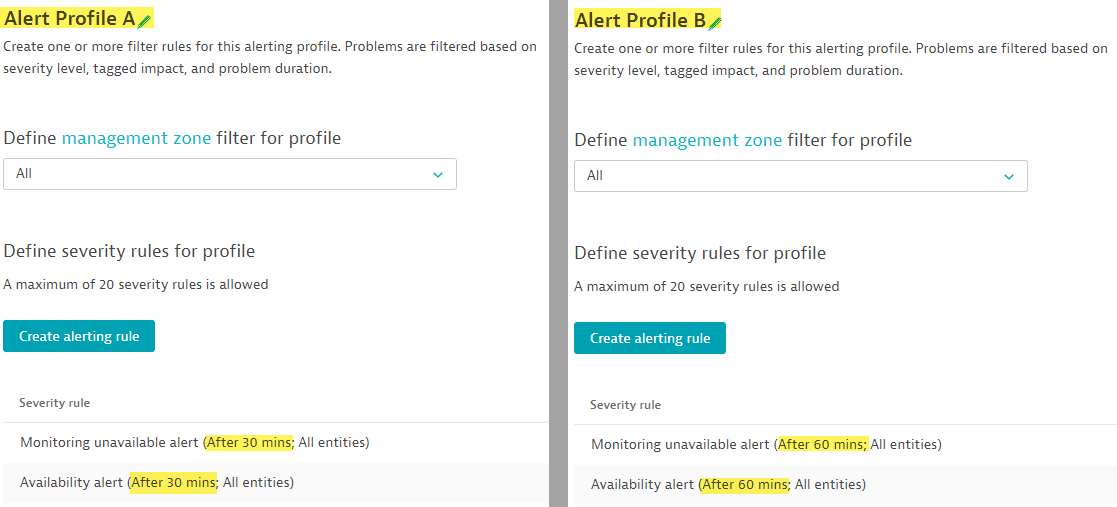
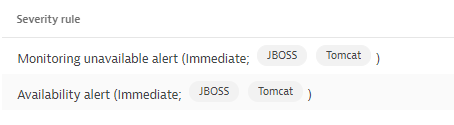
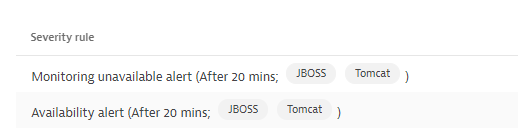
 As it relates to the alert profile, Lets say you have two Profiles A,B. A is set to alert on availability after 30 mins, and B set to 60 mins :
As it relates to the alert profile, Lets say you have two Profiles A,B. A is set to alert on availability after 30 mins, and B set to 60 mins :
Now lets say your Host '123' is the last host rebooting in your patch night. That should be up by 4am and your Option 3 Maintenance window expires at 4am. This is the flow of the event that should be expected with this set up.
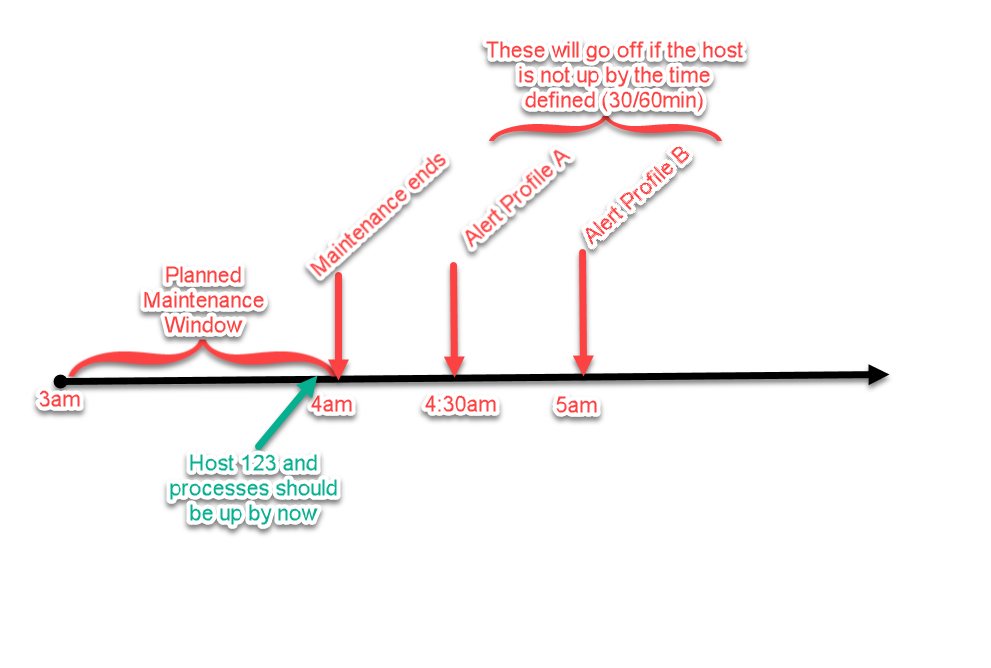
-Chad
time-line.png
{kind=link}
96 KB
alert.png
{kind=link}
27 KB
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Jan 2020 09:13 PM
Its very interesting that your services were still down but Dynatrace viewed them as up - Support might want to look at that to ensure there is no bug, especially if everything is set to alert when its down, and you can verify on your end.
-Chad
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
09 Jan 2020 02:01 PM
Chad:
Awesome explanation and thank you so much for the time you spent laying that all out.
I tested this set up yesterday and did not get the results you did. (No alert). I then conducted the test again to insure my results. This was my configuration and results.
The timeline and settings
8:15 AM Maintenance Window Start
8:17 AM Server reboot (Processes go down and stay down)
8:35 AM Maintenance Window over
8:35 AM No alerts
9:00 AM No alerts
This seems to not match the results you obtain Any thoughts as to why?
I'm opening up a case with support now to follow through and will include the results
-C



Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
09 Jan 2020 02:34 PM
Chris,
The way you have it set up looks good.
One thing to note, While your alert is set to notify immediately, there might be a 3-5 min delay. For example, if at 8am a host has high cpu, 3-5 mins into the spike it will be detected and alerted. The problem alarm will state it started at 8am, but the red and notification will kick off 3-5 mins after the initial spike.
So your set up at 8:35am the maintenance ends, I would expect and issue and alert to be raised between 8:38-8:40am for the immediate alert profile. then at 8:50am you would get the second alert from the 20 min alert profile.
I would recommend reaching out to support as there might be a bug somewhere. You should be getting alerts when these services are down based off of our configuration.
Also, If you feel that this answer is a Quality Answer to your question, please feel free to mark it as the "Best Answer" as well as reward the user who provided it by clicking "Reward User"
-Chad
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
28 Apr 2021 02:21 PM
Hi there,
We have opened a support ticket (SUP-71570) and got confirmation about the behaviour from support:
"with v1.215, events of type Time Series read alerting, Event REST API, Synthetic events will be alerted after maintenance window ends but all other events won't be eligible for it"
So having a degraded service (slowdown or failure) which degraded during a maintenance window and is still degraded after maintenance ends will not send an alert. We would have expected an alert to be sent after the end of maintenance but this scenario is not supported by the product.
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
18 Feb 2022 06:27 PM
wow, i had no idea this same question goes back to 2019. Even today there is confusion and need for adjustment to this logic. Any chance Dynatrace is working on improving this with customer feedback?
HigherEd
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
17 Mar 2022 01:07 AM
I am hoping Dynatrace would look into the issue and provide us some relief, but we have implemented a solution outside Dynatrace. We are handling the incident creation by MOM, we provide the maintenance windows details to MOM and control the incident creation based on clearing event from DT. We also create the maintenance windows in DT so we don’t skew the AI and frequent detection.
Thanks in advance, Raj
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
06 Apr 2022 04:13 AM
I have created a RFE - can you all vote? Please add anything more if the existing would not meet.
Thank you
Thanks in advance, Raj
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Dec 2022 10:32 AM
For information of anyone who visits this thread, I can see that product idea for feature discussed here is officially assigned to "Completed" status 😃
Featured Posts
