This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Alerting
Questions about alerting and problem detection in Dynatrace.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Alerting
- What JVM metrics are captured by OneAgent by default and how these metrics and custom metrics are used by problem detection AI
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
07 Aug 2019 06:08 PM
it's my understanding that DT will (by default) monitor the JVM metrics and associate any out-of-range (out of baseline) values with a problem identification using AI
For example a GC pause might trigger a spike in CPU usage. An alert on CPU usage might trip a custom alert. However, if the CPU spike does not impact service performance posture, then it essentially become a false positive. How does the DT Problem Identification AI uses custom metrics along side default metrics to decide appropriate action to cut down false positive alerts? Or custom alerts and metrics are not used by the AI?
The key question is, should we rely on Dynatrace’s ability to detect problems or should we also import custom metrics using JMX plugin to monitor JVM internal health for preventive monitoring? IF we did the latter will there be any conflicts on the custom metrics/alerts?
Solved! Go to Solution.
Labels:
- Labels:
-
java
-
problems classic
4 REPLIES 4
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Aug 2019 09:58 AM
Davis AI is triggered mostly by real user affecting events such as service and application error increases, slowdowns or process crashes. In those cases Davis AI follows all the transactions running through the unhealthy service and automatically analyzes all the thousands of individual metrics of the underlying infrastructural nodes (no matter if those are built in metrics or custom metrics such as JMX or OneAgent Extension metrics).
In case a metric shows an abnormal behaviour just before the problem was detected Davis highlights that in the root cause section of the problem, as it is shown below:
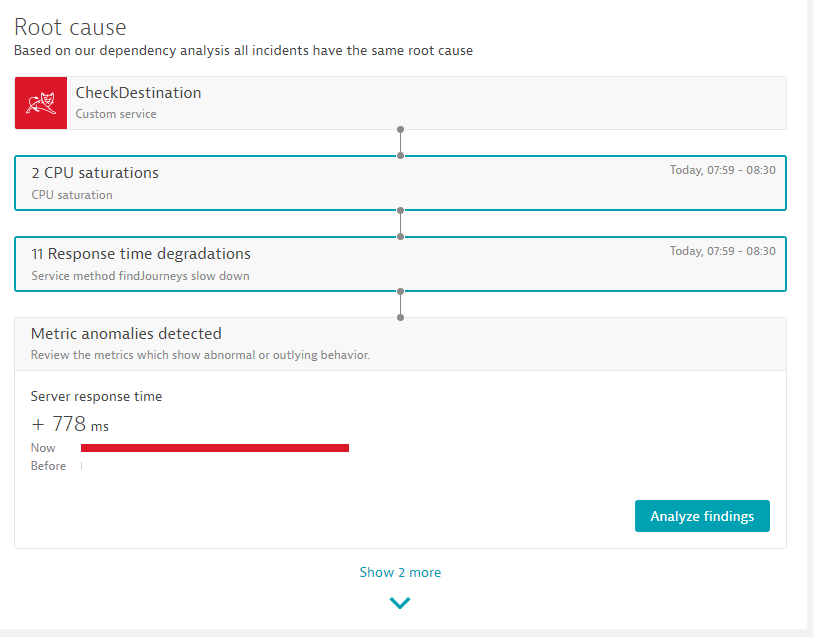 Those metric anomalies do not trigger false positive alerts as those are only analyzed during an already open problem.
Those metric anomalies do not trigger false positive alerts as those are only analyzed during an already open problem.
Best greetings,
Wolfgang
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Aug 2019 03:58 PM
Thanks Wolfgang!
Following up on the abnormal behavior identification for a problem; let's says we are collecting JVM threadpool metrics using JMX plugin and due to thread mutex issues this pool became exhausted.
Will the AI identifies threadpool metrics in the problem identification?
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Aug 2019 04:12 PM
if your JMX metric changes its behaviour right before the problem is raised (say within 15min before the problem start) I would say yes. Of course this very much depends on timing and how significant that metric change is.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
09 Aug 2019 06:05 PM
Thank you! @Wolfgang B.
Featured Posts
