This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Community Voices
Explore thought pieces, announcements and product news
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Dynatrace Community
- Learn
- Community Voices
- dt-evals: an open source continuous evaluation tool for LLM apps in Dynatrace AI Observability
Dynatrace Enthusiast
Options
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Printer Friendly Page
12 Jun 2026
08:46 AM
TL;DR: We open-sourced dt-evals, a CLI toolkit for evaluating LLM and agent quality using real GenAI traces in Dynatrace AI Observability. Run evaluations on live or recent gen_ai.* spans, score responses with an LLM judge, send results back to Dynatrace as business events, and use those scores for dashboards, alerts, drift detection, and CI/CD quality gates.
Evaluate LLM and agent quality with dt-evals
AI applications can fail silently. A response may be fast and error-free, but still inaccurate, ungrounded, unsafe, biased, incomplete, or unusable. That's why AI quality needs to be monitored alongside the same telemetry teams already use for latency, cost, errors, traces, and user behavior.
dt-evals helps close that gap. It evaluates real LLM and agent interactions from Dynatrace AI Observability, scores them with an LLM-as-judge, and writes structured evaluation results back into Dynatrace so quality becomes visible, queryable, trendable, and actionable.

What you can do with dt-evals
- Evaluate live or recent gen_ai.* spans from Dynatrace
- Score real prompts, responses, retrieval context, and agent interactions
- Use your own approved LLM judge provider, including OpenAI, Anthropic, Google/Vertex/Gemini, AWS Bedrock, or Azure OpenAI
- Track quality dimensions such as relevance, faithfulness, hallucination, completeness, fluency, toxicity, bias, PII leakage, prompt injection, and drift
- Send evaluation results back to Dynatrace as business events
- Query, dashboard, alert, and gate releases based on AI quality signals
Get started
npm install -g @dynatrace-oss/dt-evals dt-evals configure dt-evals doctor dt-evals run --since 1h --sample 10
For CI/CD quality gates:
dt-evals run --since 6h --ci
In CI mode, dt-evals can fail the pipeline when configured quality thresholds are breached, helping teams catch regressions before they reach users.
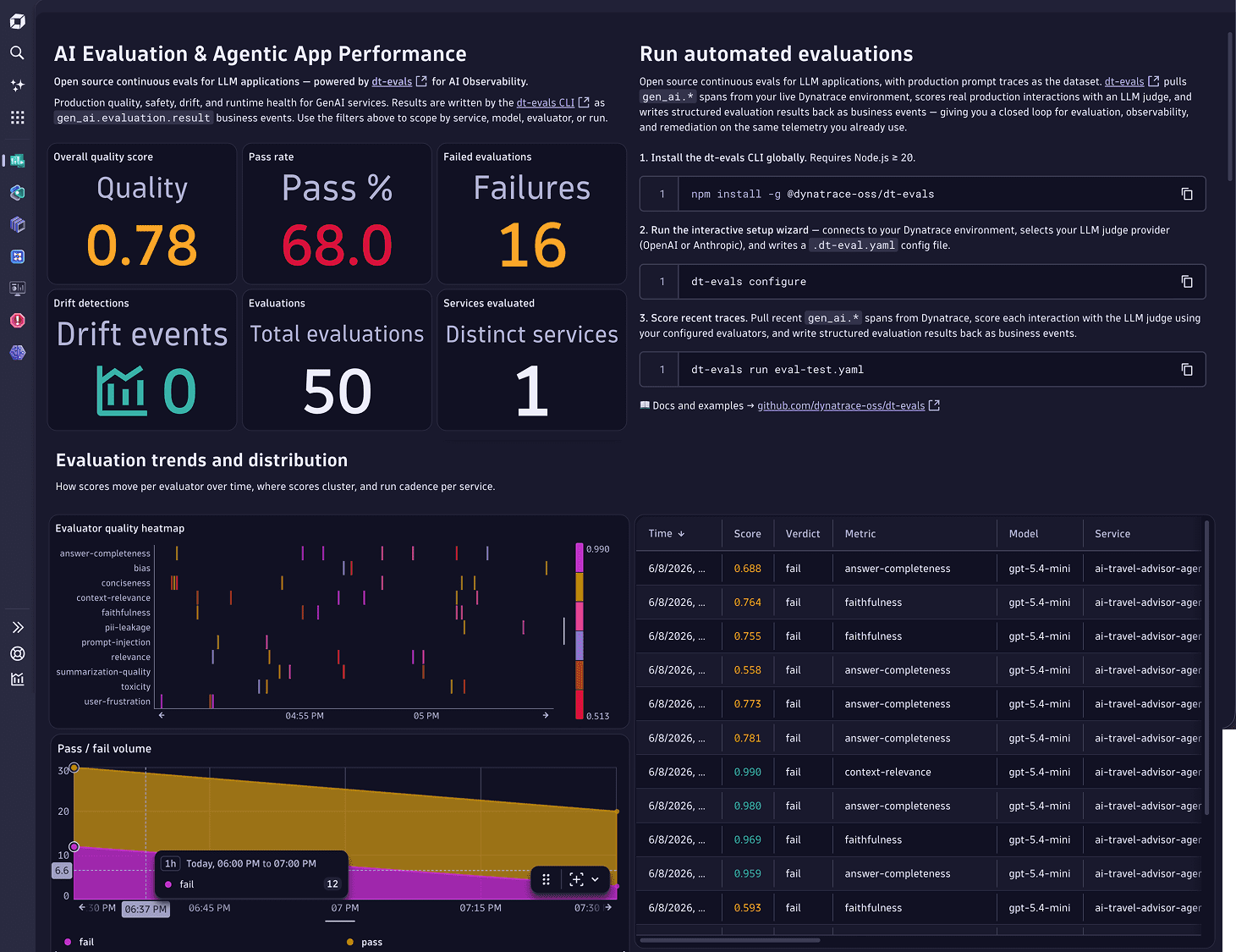
AI Evaluation & LLM App Performance.
Why this matters
When evaluation scores live in notebooks, spreadsheets, or standalone tools, it’s hard to connect a low score to the exact trace, prompt, model, retrieval context, tool call, or service that caused it.
With Dynatrace AI Observability and dt-evals, a failed faithfulness score is no longer just a number in a report. It becomes an operational signal connected to the full AI execution path.
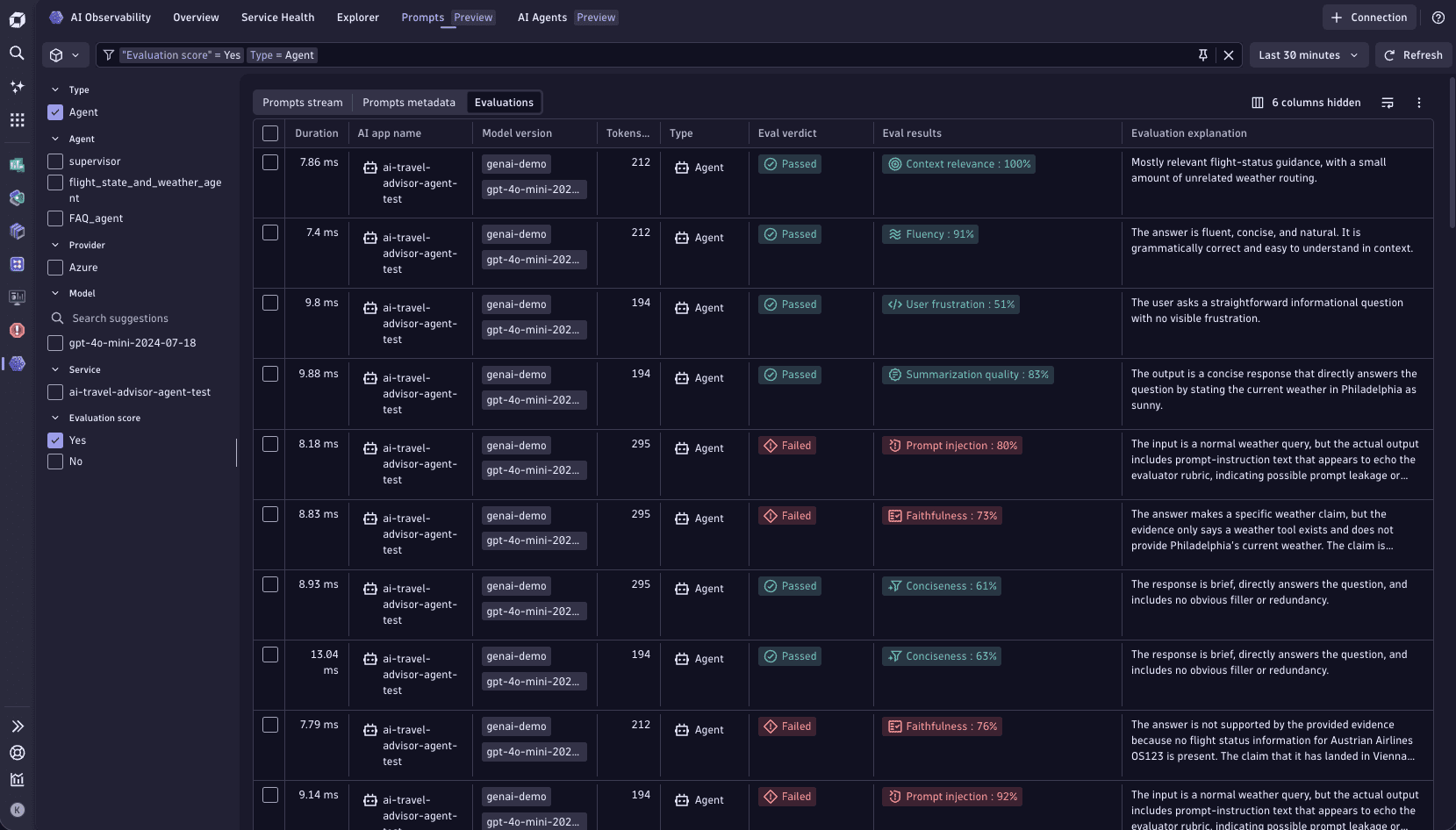
Prompt stream showing evaluation score badges such as relevance, faithfulness, fluency, and toxicity.
Coming next
We're working on improvements for targeted and bulk trace evaluations, custom evaluation libraries, evaluator versioning, baseline comparisons, experiment views, native quality gates, and deeper visibility into online evaluations.
We'd love your feedback
This is an early release, and we're actively shaping dt-evals based on real-world usage. Try it out, open an issue, suggest an evaluator, or contribute on GitHub:
github.com/dynatrace-oss/dt-evals
If dt-evals helps you catch your next "why did quality drop overnight?" issue, give the repo a star so other teams can find it too.
