This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Dashboarding
Dynatrace dashboards, notebooks, and data explorer explained.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Dashboarding
- OpenShift: getting the delta value of Kubernetes metric
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Feb 2022
03:22 PM
- last edited on
25 May 2023
02:30 PM
by
![]() Michal_Gebacki
Michal_Gebacki
Hi Dynatrace Community.
I'm wondering if anybody has figured out how to get a delta value for the builtin:cloud.kubernetes.pod.containerRestarts metric. A few of us are looking to alert on this value but since it's always pulling in the absolute value we find it difficult to set up alerting here. We can use the 'Code' section if there's a way to calculate this delta value ourselves else we're wondering if this can be added to a roadmap.
When looking at Container Restarts within Dynatrace, we see a huge incremental line (count of 600+) so we know there's an issue with this specific event but having a "container restart" value doesn't always mean there's an issue currently. If a container restarts 10 times in 1 hour due to a connection issue and then re-establishes its connection, it'll run healthy but the container restart value for that pod will still be 10 until the pod itself is recycled. If the pod continues to run for another 24 hours after that and restarts five more times, the value will show up as 15.
What we'd like to get instead is the delta value. If we look at the time period when the pod was restarting we should see it going from 1 to 10 but when it stabilizes we'd like to see that pod restart value go zero so when it starts restarting again we can see it go from 1 to 5 instead of it going from 10 to 15 (basically by taking the current pod restart count and subtracting it from the previous value).
By having this, we hope to add custom alerting to say if the restart value is greater than 0 for a 10-minute period to create an alert. Right now we'd have to set it as a ceiling (over 10 restarts, for example), and then to ensure we don't get false alerts after a resolution we'd need to manually destroy the pod so a new one comes up in order to "reset" the container restart value-adding extra toil.


Thanks!
Travis Ottelien
Solved! Go to Solution.
Labels:
restarts_dynatrace.png
22 KB
restarts_openshift.png
18 KB
7 REPLIES 7
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
08 Feb 2022 03:47 PM
I was thinking about this more and we'd never see it go from '1 to 10' or '1 to 5' when doing delta (unless somebody is running more than one container. If running one container it would always fluxuate between 0 and 1. But everything else still stands.
Travis Ottelien
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
20 Jul 2022 09:59 PM - edited 20 Jul 2022 10:07 PM
Have you tried the "delta" operator already?
builtin:cloud.kubernetes.pod.containerRestarts:sum:delta
docs: https://www.dynatrace.com/support/help/shortlink/api-metrics-v2-selector#delta-transformation
Looks like:

{kind=link}
{kind=link}
Question to me is what would be the right value extraction aka time aggregation function before the delta operator. The aggregtion simply defines who data points (in a bag) for a time slot are merged.
SUM, AVG,..?
fyi @florian_g !
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
21 Jul 2022 08:07 AM
Hi @travis_ottelien ,
here's an example how to deal with this metric today: https://github.com/Dynatrace/dynatrace-api/blob/master/metric-example/metric-expressions-for-k8s.md#...
Please note, that we're currently migrating a lot of these metrics. We also understood that this delta expression is too complex, which is why we also plan to convert the container-restart-metric into a counter metric. This will allow you to perform a simple sum instead of a complex delta operation. Please read all about the migration and availability of new metrics here.
I'll also update the metric example page shared above in the upcoming weeks to work with the new metrics.
Best,
Florian
Brace yourselves - cloud-native deployments are coming.
Contribute to Dynatrace/dynatrace-api development by creating an account on GitHub.
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
21 Jul 2022 03:49 PM
Hi Florian,
I work with Travis, actually we tried testing the container restart per pod metric using the delta transformation ,but unfortunately the container restart count showing in dynatrace is not matching with the actual count we see in openshift.
For one of the pod we see that the total container restart count is 3 from 19th july to till date.but when we check the same in data explorer its showing different value for this time frame.Could you please help us here if we need to add any other transformation like fold or any other improvisations here.
PFB the details for reference where you can see container restart count is 3 and the data explorer showing other value
DT.JPG
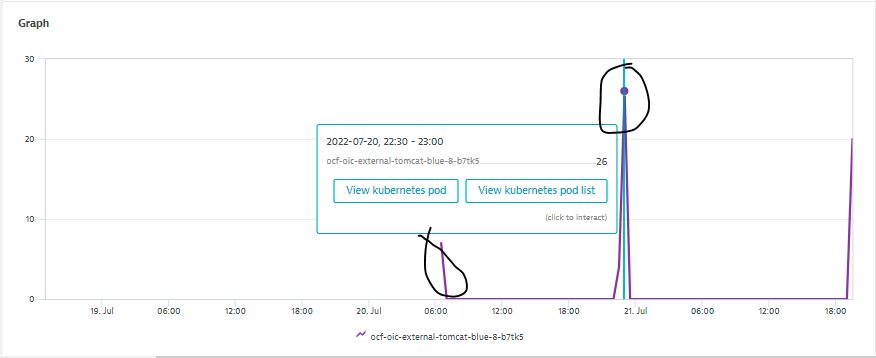{kind=link}
35 KB
{kind=link}
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
21 Jul 2022 04:07 PM
HI Folrian,
More over as you have mentioned above we see that builtin:cloud.kubernetes.pod.containerRestarts metric is gonna be replaced with the new one builtin:kubernetes.container.restarts ,So just wanted to confirm here that its just not gonna be about renaming the metric right ,the new metric can be expected to have a better functionality in evaluating the data and give the much more mature results as expected compared to the old one right, just wanted to confirm on it.
Regards
Sriram
Please note, that we're currently migrating a lot of these metrics. We also understood that this delta expression is too complex, which is why we also plan to convert the container-restart-metric into a counter metric.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
25 Jul 2022 06:16 AM
Hi Sriram,
yes, the metric is going to be renamed AND improved. The planned release is with AG 247, which is planned to start roll-out in about one month.
In your screenshot example, my best guess is, that some AG restarts might be the problem. Today, with the current metric, you might see spikes in container restarts after AG restarts. This is due to the fact, that the metric counts total container restarts and the expression calculates the delta to the previously reported total restarts. In case of a non existing data-point (cause the AG did a restarts and didn't report data), the expression will cacluate a delta to zero. So if your pod had already 20 container restarts and at this point the AG restarts, the expression will calculate 20-0 -> showing you 20 container restarts, which is of course wrong.
If you want to digg deeper into that and fix it for this old metric, I'd ask you to talk to our support about it, so they can have a closer look. Honstely, I would recommend to wait until AG 247 and not waste time into a temporary complex solution which is going to be obsolte in about one month.
Best,
Florian
Brace yourselves - cloud-native deployments are coming.
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
27 Jul 2022 09:35 AM
Hi Folrian,
Good day!!
Thanks for the details ,as suggested we will until the AG 247 version so that we can use the new container restart metric. Beforehand we would like to know if you have already tested the new metric builtin:kubernetes.container.restarts successfully in you sand box environment and if so is it giving the results as expected or is this metric not yet tested fully?
Regards
Sriram
Featured Posts
