This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Dynatrace API
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Dynatrace API
- Re: Aggregation on metrics exposed through API
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
13 Feb 2018 11:19 AM
Hi,
What is aggregation being used for problem pushed through API for infra, service, application when we are using automatic anomaly detection or Custom threshold for these metrics like Disk, CPU , Memory etc. Whatever exposed through API.
If I want to change aggregation for custom threshold , how can I do that
Regards
Suresh
Solved! Go to Solution.
Labels:
- Labels:
-
dynatrace api
4 REPLIES 4
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
13 Feb 2018 12:18 PM
For slowdowns in automatic mode we alert on 50th and 90th percentile. Same for service response times as well as applications.
There is no way of changing the aggregation type for custom thresholds but what you can do is to define a custom alert where you have the option to choose between the aggregation types.
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
14 Feb 2018 04:51 AM
Thanks Wolfgang,
Do we have any timeseries Id for Automatic Alerts generated by dynatrace.
for example CPU Saturation , it will create a problem if cpu usage cross 95%. But I did not find any timeseries for that. I can see timeseries for other cpu usage metric like stealtime, idle time, system usage but not the overall usage of CPU.
Regards
Suresh
disk-anomaly.png
{kind=link}
18 KB
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
14 Feb 2018 07:29 AM
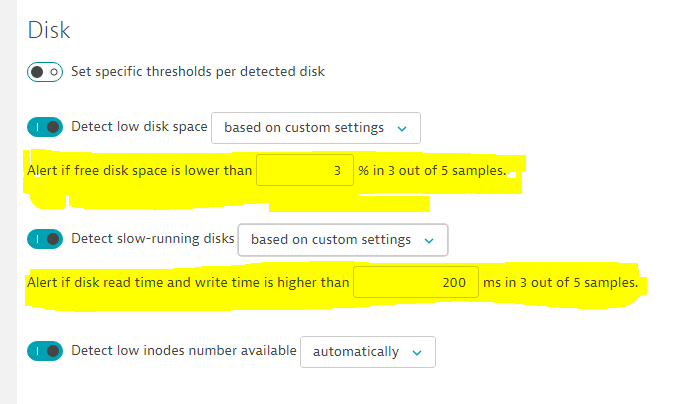
Disk aggregation that is used is the average. Availability for process is based on a process instance count where we use the min aggregation for alerting on the minimum instances running thresholds. For resources most of the time its also the average aggregation type.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
14 Feb 2018 02:02 PM
Thanks Wolfgang,
Do we have any timeseries Id for Automatic Alerts generated by dynatrace.
for example CPU Saturation , it will create a problem if cpu usage cross 95%. But I did not find any timeseries for that. I can see timeseries for other CPU usage metric like steal time, idle time, system usage but not the overall usage of CPU.
Regards
Suresh
Featured Posts
