This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Dynatrace Managed Q&A
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
Looking to upgrade from Dynatrace Managed to SaaS?
See how
- Community Home
- Platform
- Dynatrace Managed Q&A
- Multi-node setups for failover and data redundancy
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
20 Oct 2018
08:56 AM
- last edited on
24 Feb 2023
12:34 PM
by
![]() Karolina_Linda
Karolina_Linda
In the documentation, I read that recommended multi-node setups for failover and data redundancy is 3-node cluster.
Anybody has idea why it isn't two, but 3? Isn't two-node cluster can already cater for that?
Best Regards,
Wai Keat
Solved! Go to Solution.
Labels:
- Labels:
-
dynatrace managed
Reply
3 REPLIES 3
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
20 Oct 2018 10:39 AM
With 2 nodes you can't guarantee aspects such as partition tolerance. Two-node clusters are typically feasible only in active-passive setups (speaking generally).
Dynatrace Ambassador | Alanata a.s., Slovakia, Dynatrace Master Partner
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2018 11:23 AM
If I recall correctly this is due to the replication of the cassandra cluster which needs three nodes for a high availability setup.
Dynatrace Certified Master - Dynatrace Partner - 360Performance.net
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Oct 2018
10:48 AM
- last edited on
09 Apr 2021
02:34 PM
by
![]() MaciejNeumann
MaciejNeumann
To fully understand this concept you need to know what is a primary node in cluster.
Majority of things that cluster nodes do can be done by any of them - e.g. processing data from agents, preparing data for charts, filtering logs and so on. Any node in any moment can perform these tasks so in case of node being down, other node can do the processing instead.
However, there are few tasks that need to be done only on one node (like cluster scalling management, billing calculation, updates management). Node which do these things is called primary and is chosen autmatically by "leader ellection" algorithm.
If primary node for some reason goes down, after a while other nodes will recognize this situation, they will choose new primary and cluster will work correctly.
So far so good, everything seems fine even for 2 nodes cluster: if primary goes down, second node becomes a new primary and can do tasks "primary tasks".
Unfortunately there is one scenario that's more difficult than "node going down" - network problem. In three nodes (let's name them A, B and C) cluster in normal situation all nodes can communicate each other via network.
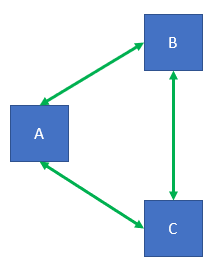
When connection to node A is broken, we've got cluster split into two parts: B+C and A. B and C can still communicate.

Leader ellection algorithm allow two choose the primary node only if cluster node can communicate to more than half of cluster nodes (including itself). Nodes remembers that their cluster size is 3. In this case primary will be chosen out of B and C nodes (B can communicate with B and C which is 2/3 of all nodes, the same is true for node C, while A sees only itself).
If cluster consists only of 2 nodes (X and Y) then after network failure X can communicate only to itself, the same is true for Y. No node can be chosen as primary because 1/2 is not more then half.
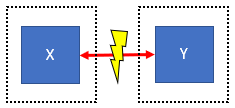
Now we're close to conclusion. You may ask why we use the rule of being able to communicate to more than half of cluster nodes. If we don't apply that rule, in second scenario both nodes X and Y may "think" they're primaries (both "thinks" that other node is down) and start performing primary-only tasks which can lead cluster to go into corrupted state.
Please notice this is common feature of clustered software. I mean the same is applicable for Cassandra, Elasticsearch (both are used by Dynatrace cluster) and many others.
Reply
Featured Posts
