This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Open Q&A
If there's no good subforum for your question - ask it here!
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Open Q&A
- Process group detection rules, extracting the identifier
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019 09:47 AM
Hi,
I have some WAS processes which are named in a way that's difficult for Dynatrace to properly group them. I'm using the attribute "WebSphere server" for this. There's first a version number in the middle, and then in the end a node number. So e.g.:
NAME_01_APP_01
The NAME is a constant for all processes, and I'm using that as the starting delimiter ("NAME_"). So from this, I'd like to extract "01_APP" as the process group. My question is, if I define the end delimiter as _0, does it then pick the first _0 or the last _0? So which direction is it reading the string from, from the left or from right?
Since there's no preview function available and these only take place after a restart, it's not so straightforward to test... if someone has the info, I'd appreciate it 🙂
Solved! Go to Solution.
Labels:
- Labels:
-
process groups
Reply
9 REPLIES 9
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019 11:36 AM
Actually the best method here is to utilize the DT_CLUSTER_ID and DT_NODE_ID environment variables for those WebSphere instances and not dealing with the process group detection rules at all.
Just set your desired values for the server process in WAS admin console in :
Application servers > <server > Process definition > Environment Entries:
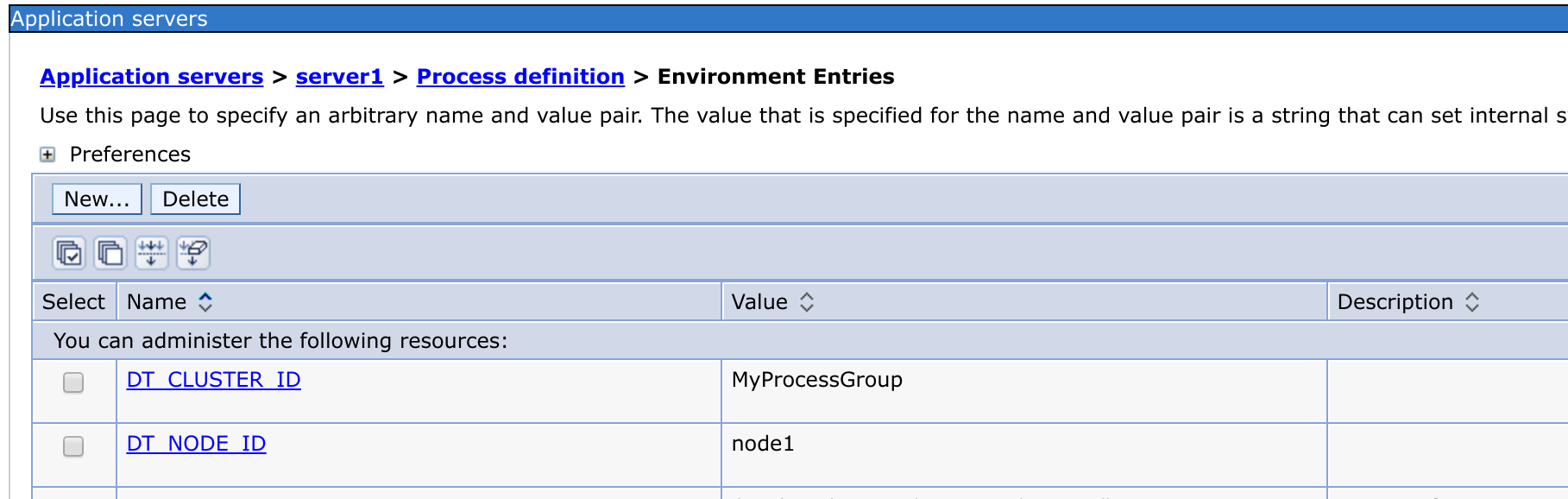
And fully restart the WAS process.
From the example above, your WAS will be a member of MyProcessGroup and will be identified as node1.
Dynatrace Ambassador | Alanata a.s., Slovakia, Dynatrace Master Partner
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019 01:16 PM
Thanks Julius! That does indeed look like the correct way to do it. But for clarity's (and documentation's) sake, I still would like to understand how that PG detection rule works in the example I presented; how is that "end delimiter" evaluated in case the substring appears more than once within the attribute? I think that's good to understand for other cases, anyway.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Oct 2019 07:29 AM
Hey,
Having now tested this. I can confirm that the end delimiter is being read from the right hand side of the string. So my PG detection rule in this case worked without having to edit the env. variables; NAME_01_APP_01 and NAME_01_APP_02 went into processes 01_APP (Node01) and 01_APP (Node02).
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Oct 2019 07:43 AM
Glad it worked for you.
Process group rules is really an area to improve. For example I'm really missing the regex functionality here (extract the process group name and node id by using capture groups).
Dynatrace Ambassador | Alanata a.s., Slovakia, Dynatrace Master Partner
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
30 Jun 2023 01:28 PM
This is an old topic, but it may still be relevant to some.
@kalle_lahtinen can you tell if this situation is still the case (and perhaps still in place)? And if so, perhaps you can share the details on how you set things up on both sides?
Kind regards, Frans Stekelenburg Certified Dynatrace Associate | Cegeka.com, Dynatrace Partner
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
30 Jun 2023 01:44 PM
Hi,
Unfortunately I no longer have access to that particular Managed environment, where that setup was in place. So I cannot confirm whether the rule behavior has changed since then. On the other hand, I would assume it's most likely still the same.
To repeat the finding above:
Using the example string "NAME_01_APP_01", when I define the end delimiter there as _0, it stops after "APP", not after "NAME". So the end delimiter (at least at the time) worked so that the string is being read from the end of the string until there's a match. Does that make sense?
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
30 Jun 2023 02:10 PM
Thanks, so I take it on WebSphere side the naming convention according NAME_01_APP_01 was applied, and you used the process group (advanced) detection rules (not process group naming).
Something like this:

Kind regards, Frans Stekelenburg Certified Dynatrace Associate | Cegeka.com, Dynatrace Partner
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
30 Jun 2023 02:21 PM - edited 30 Jun 2023 02:29 PM
Hi,
Yes, that is precisely correct. What is slightly misleading there IMO is the text "next occurrence of ...", because if and when the string is being read from right to left when matching the end delimiter, it should actually say the "last occurrence" 🙂
Edit: Correcting myself right away, actually the first underscore is already part of the first rule "NAME_", so it makes sense why it's skipped. So when matching the end delimiter, I suppose only "01_APP_01" is considered, and there _0 is found only once 🙂 So in the end I'm not sure what the answer is after all... The problem so to speak was that I got it to work on the first attempt, so I didn't really have to test that thoroughly all the scenarios.
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
30 Jun 2023 02:56 PM
Yes, exactly, the _ after NAME was noticed, and I think a significant part of your delimiting success 🙂 Thanks.
Kind regards, Frans Stekelenburg Certified Dynatrace Associate | Cegeka.com, Dynatrace Partner
Featured Posts
