This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Synthetic Monitoring
Browser monitors, HTTP monitors, synthetic locations.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Synthetic Monitoring
- Re: Private synthetic locations and test frequency - load balancing across cluster activegates
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Nov 2020
03:35 PM
- last edited on
10 Mar 2023
03:39 PM
by
![]() Ana_Kuzmenchuk
Ana_Kuzmenchuk
Hello everyone,
Could you please help me to understand what would happen with the following setup.
Let's imagine that with the DT managed we have Cluster Activegates setup for Private Synthetic tests. There are 8 cAGs assigned to 4 Private Synthetic locations - 2 nodes per location.
We also have a total of 100 HTTP monitors set up in the cluster for several tenants. The frequency of tests is the same for all tenants/tests - once every 5 minutes.
I what to understand how DT/Cluster ActiveGates will schedule and distribute the above load among themselves.
In the above case - how frequently each cAG will test the particular URL? The frequency of once every 5 min means that location A will test the URL, 5 min later location B, then 5 min later location C, and finally location D or every location will test the URL every 5 min?
Because there are 2 nodes per location, how does the workload is divided? Will node1 in a location test the particular URL first and one the next iteration it will be node2 which will be testing the same URL? Or there is some more complicated logic behind it?
Thanks
Solved! Go to Solution.
Labels:
12 REPLIES 12
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Nov 2020 03:57 PM
For both Browser Monitors and HTTP Monitors, the frequency you set is how often it will run on each location. So if you have 4 locations and the frequency is set to 5 minutes the monitor will run every 5 minutes on each of the 4 locations.
For Browser monitors, the workload for a location is split across both ActiveGates. It is done by how busy they are. So a monitor could run on 1 AG for one iteration and the other the next or it could run on the same AG multiple times.
For HTTP Monitors, I believe it works slightly differently and each HTTP monitor is scheduled to run on a specific AG rather than executions split across the 2.
Synthetic SME and community advocate.
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
24 Nov 2020 12:12 AM
Hello Hannah, thanks for replying.
I've asked the question because I've seen quite an imbalance in CPU load on Cluster ActiveGate nodes assigned to the same Private Synthetic location.
Take a look at the screenshot below. There are three nodes/Cluster Activegates assigned to one particual Private Synthetic location. The configuration of the VMs is identical - M size for the the Cluster ActiveGate. All synthetic monitor tests setup across differnt tenants are http tests just checking an URLs for the particual tenant every 5 min. But one node is much more utilized than other two.
How the load can be districuted across all therr nodes in the private synthetic location for my scenario? I don't want to add additional nodes to the location or scale up the VMs.
Thanks.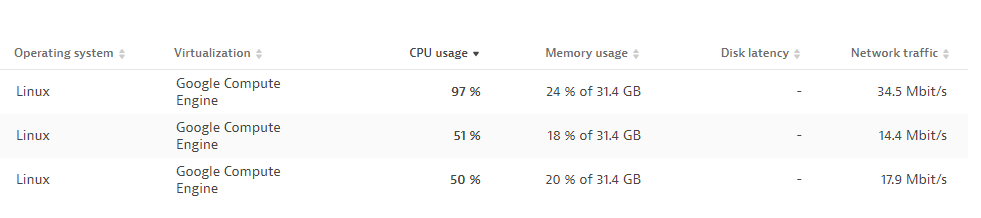
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
24 Nov 2020 10:12 AM
Hi Iraki,
As a member of the Synthetic DEV team, I can confirm everything that Hannah said.
HTTP monitors are split among AGs in the location by monitor definition. So one monitor is executed by the same AG every time. There is a chance that some monitors consume more resources than others and the sharding was so unfortunate in your case that the discrepancy of resources usage is visible.
The good news is, we have implemented new scheduler for HTTP monitors on private deployments. Such monitors will be executed by Synthetic engine as browser monitors. There will be no sharding at all. The visits will be split among nodes in location based on their capacity and utilization. Hopefully, that would balance resources consumption more equally. In fact, we have already started to migrate customers to this new solution since version 205.
Regards,
Tomek
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
25 Nov 2020 01:27 PM
Tomasz,
Thanks for the insightful reply. If we move/redeploy our Cluster ActiveGates to release 205 will it automatically take care of the load problem?
Also, what would you recommend - upgrade the current activegates to 205 or redeploy them from scrat with the latest version?
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
25 Nov 2020 01:38 PM
Irakli,
Unfortunately, it won't turn on automatically for safety reasons.
It's a very big change from the technical point of view - not only a different scheduling mechanism is used but also a different component will execute HTTP monitors (Synthetic engine instead of ActiveGate). Because of that, we want to stretch the migration process in time and do it in phases, migrating tenants one by one at the same time monitoring the situation.
Once we are sure the whole solution works fine for the chosen groups of tenants we will turn it on by default. After that, the migration should occur automatically.
A fresh installation would not be necessary, just a standard upgrade.
Regards,
Tomek
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
30 Nov 2020 07:26 AM
Tomasz,
If I understand correctly your reply, just an upgrade to v 205 to the cluster activegates is not sufficient to see load distribution to even out and some other actions are required?
If so, what are these actions?
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
30 Nov 2020 11:49 AM
Irakli,
If you could wait till the feature is fully supported, then no further actions would be needed.
If the resource consumption imbalance is really that crucial and you would like to be an early adopter of the feature then I would need to check how to arrange that. An upgrade to 205 is a prerequisite. Perhaps you could share a link to the environment, we could check whether the deployment is ready to be re-configured (valid versions, synthetic engines installed etc) .
Regards,
Tomek
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
02 Dec 2020 07:40 AM
Tomasz,
Thanks for the reply. We'd probably wait until v205 and newer releases are out. At this moment we decided to reduce test run frequency to reduce the load on cluster activegates.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
15 Feb 2021 12:47 PM
Hello @Tomasz W.
Could you please tell me how the load of test will be distributed between AG?
We have 1 location for 4 AG, while there are 2 large AG in 2 Small AG.
Does balancing take into account that ag size is different or better we should make them the same size?
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
15 Feb 2021 01:13 PM
Mikhail,
Once it's the synthetic engine that executes HTTP monitors (not AG), there would no static distribution among nodes. Instead, the nodes would ask for as many visits as they are capable of executing at a given moment in time.
If the location has not much to do it is possible that there would be fluctuations depending on which node had better luck to get the work. Still, that could change every few seconds.
What is the most important here, there would be no static shards whatsoever.
Every node has the same chance of retrieving the monitor that use up a lot more resources than others (if there is such one).
Regards,
Tomek
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
20 Feb 2021 09:15 AM
thanks for the answer!
Could you please tell me the new functionality has been released from version 205?
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Feb 2021 09:53 AM
It's not that trivial. The functionality has been already released but turned off by default. It can be turned on for desired tenants.
Since cluster version 211, the functionality has been turned on by default. The prerequisite is that all AGs in a given location are in the right version (at least 207 I think or 205)
Reply
Featured Posts
