This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Real User Monitoring
User session monitoring, key user actions - everything RUM.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Real User Monitoring
- GCP, Kubernetes, IP changes, and wildcards together seem to not play nice in Dynatrace - Are we the only ones?
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
06 Jul 2020 08:51 PM
Greetings all!
One of our teams is running on GCP using Kubernetes and has the same Dynatrace problem raised daily which is a "Response time degradation". We have been trying for weeks now to figure out how to isolate specific requests so that we can fine tune the anomaly detection around them.
Sounds straight forward, right? - Nope 🙂
As we have worked to figure this out, I have found more and more challenges.
The first thought was key requests, but there are multiple limitations on why that will not work.
IP Changes
The IP for the Elasticsearch services change anytime there is an OS update and / or Kubernetes update. Because key requests are configured at the service level, it is then lost once instances go away and new ones come in.
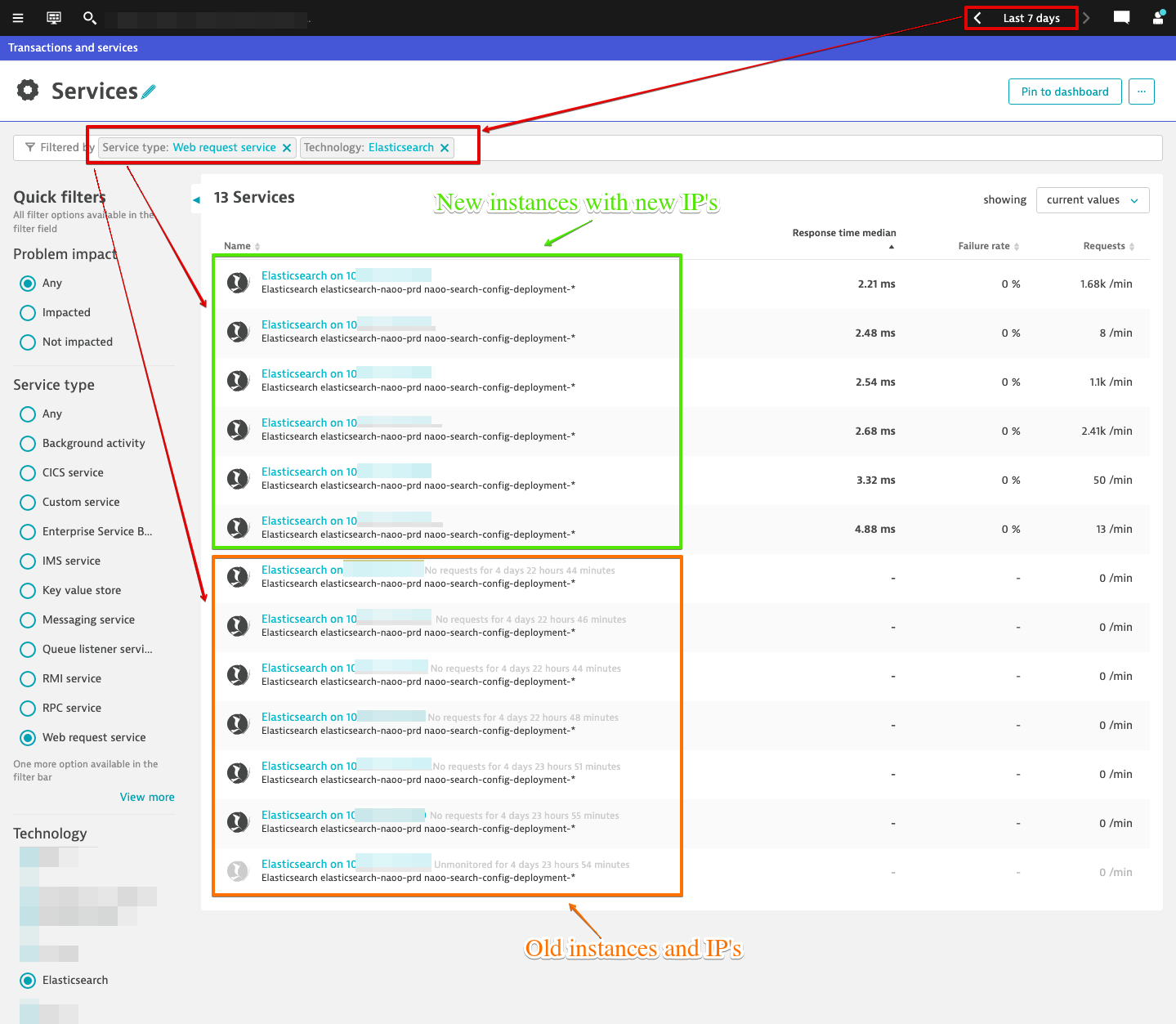
The name of the Elasticsearch service is always "Elasticsearch on <IP>:PORT" in Dynatrace. This is an easy fix through service naming rules which I later did, however that still did not provided any added benefit.
Service Merging
Then of course there is service merging. That too is a great feature until you come to this type of situation. You can merge all day long, but as soon as those instances go down and new ones come up it is back to the drawing board. There really needs to be a configuration option to allow for auto-merging for this approach. I have created an RFE on this approach which I have provided a link to below.
Web Request Naming Rules
After all that, I went back to the problem at hand which is the Dynatrace problem being raised daily. A lot of the web requests have paths which contain unique ID's. In that case you would want to just create a web request naming rule to wildcard that part.
Great! Except...
That can only be done at the service level once again meaning that as soon as these instances go down and new ones come up that web request naming rule is history. This leads me to believe that there should be a way to configure web request naming rules at the process group level where the web request lives and I have also created an RFE for this approach which I have provided link to below.
Elasticsearch OneAgent Extension
We though perhaps by utilizing this it may provide deeper insight and provide more information to the Dynatrace software to deal with frequent IP changes, but we were never able to get past the configuration portion of the extension. Without going into too much detail, working with Dynatrace support it was found that the OneAgent extension for Elasticsearch executes its connection from the host to the pod and not from inside the pod. We do not expose the Docker port to the host for security reasons and as a result, the extension is unable to make a connection. An RFE was created for this as well which I have provided a link to below.
I feel like I am running around in circles chasing my tail on this one. I am so frustrated trying to figure this out that if I had any hair left on my head, it would now be gone 🙂 I should state that all the above approaches were just that, attempts to address the goal of isolating specific web requests and then not losing those settings due to IP changes.
Has anyone else ran into this? Have you found a solution if you have?
I have created 3 different RFE's based off my findings in trying to find a solution to this.
- RFE: Add ability to configure web requests naming rules at the process group level
- RFE: Add ability to establish rules which in return auto configure service merging
- RFE: Add the option for Elasticsearch OneAgent extension configuration to connect from pod
Thanks!
Solved! Go to Solution.
2 REPLIES 2
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
06 Jul 2020 10:43 PM
Service naming rules only change the 'friendly' name that you see but the underlying entity will still have the same ID hence it's easy to have things named the same way but there will still be separate logical services.
Service merging is OK in some situations but at scale and in cases like this it is not super helpful which is why it is being replaced by 'service detection rules' that allow you to tune how services are detected. Can't see from screen shot because the properties exist in the service overview page but services are typically detected from combinations of three properties: application ID, server name, and context root. The service detection api rules let you apply conditions and then transform or override these values giving you complete control over how services are detected even before they show up in Dynatrace. Keep in mind though that services can't span host groups/process groups so this assumes they are all part of the same ones.
https://www.dynatrace.com/news/blog/new-dynatrace-api-enhances-automatic-service-detection/
A bit on what goes into service detection: https://www.dynatrace.com/support/help/how-to-use-dynatrace/transactions-and-services/basic-concepts...
Since the underlying issue is the service detection this should resolve the request naming rules, but also note there are global naming rules you can set through the API.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
07 Jul 2020
12:31 PM
- last edited on
16 Oct 2023
03:25 PM
by
![]() random_user
random_user
This was exactly what was needed and perfect timing for it. Thank you!
Featured Posts
