This website uses Cookies. Click Accept to agree to our website's cookie use as described in our Privacy Policy. Click Preferences to customize your cookie settings.
Real User Monitoring
User session monitoring, key user actions - everything RUM.
Turn on suggestions
Auto-suggest helps you quickly narrow down your search results by suggesting possible matches as you type.
- Community Home
- Platform
- Real User Monitoring
- Using regex in new User Action Naming dashboard
Options
- Subscribe to RSS Feed
- Mark Topic as New
- Mark Topic as Read
- Pin this Topic for Current User
- Printer Friendly Page
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019
01:10 PM
- last edited on
19 Oct 2022
03:05 PM
by
![]() MaciejNeumann
MaciejNeumann
Hello,
previously I was able to use regex for extracting parts of URL and replace them with some identificator. I have to DT clusters on the same version 1.176. One of it has old settings with regexes, one has new one when I can define placeholder with extraction or replace rules. But "between" is not always ok, because sometimes it needs to prepare multiple rules (hundreds of uris, that are hard to cover with single url, we have multiple UUIDS there). I don't see updated docs about this topic.
I've had such cleanup rule before:
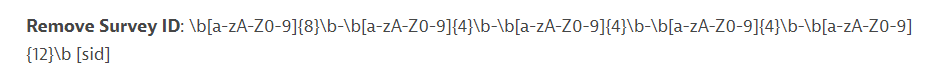
Sebastian
Regards, Sebastian
Solved! Go to Solution.
Labels:
Reply
11 REPLIES 11
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019 01:18 PM
Regex support in user action naming rules has been removed and based on my information, it won't be available in this new engine 😞
Unfortunately, I also encountered situations where regex support was handy and I was unable to replicate this behaviour using the new engine.
Dynatrace Ambassador | Alanata a.s., Slovakia, Dynatrace Master Partner
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019 01:27 PM
So I'm screwed 😉 thx
Regards, Sebastian
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019 01:33 PM
Hi,
Julius is right. We have no plan to bring regex back, but we are locking for improvements on the new naming patterns. @sebastian k. the regex you posted is that the one that you need to recreated?
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
22 Oct 2019 05:44 PM
Yes, without this I have to create 70 naming rules because of complexity of uri patterns we have there. Regex was best thing that cleaning urls framework had before so it's really disappointing that it will no go back there... This regex was covered UUID that shows up in mutliple places in URIS, sometimes more that once so simple before after isn't best idea. Sometimes uris are ending with UUID so we have to preserve proper order of rules to be sure that we will not merge similar uris that has something after UUID. In general for me it is huge issue.
Sebastian
Regards, Sebastian
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Oct 2019 06:24 AM
We are currently researching on possibilities to improve therefore your Q&A is a really good input.
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
20 Jan 2020 08:59 AM
Anytime time line for the planned improvements? We too need this functionality in order to mask sensitive information like click on bank account number. Our develops cannot make the change at the code level.
Thank you,
Yair
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
21 Jan 2020 09:16 AM
Hey Yair, while the new action naming is supposed to be simpler for our customers, we are currently looking into also supporting regular expressions, to make the definition of rules as dynamic as before. We will keep you updated on this!
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
21 Jan 2020 10:25 AM
Thank you Thomas,
I cannot stress enough how critical it is to have this functionality in order to deploy dynatrace in our organization.
Appreciate the answer on this. We will look for the upcoming updates.
Yair
Reply
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
23 Oct 2019 02:46 AM
Hi Team,
I second this as a potential candidate for an RFE to restore previous functionality to include regexp. It's hard enough without ability to copy rules to make some tweaks to multiple similar rules, and also it's not available through API.
So regex was always a good option if required, and this will surely present some blockers on converting existing rules to the new format and for converting AppMon business transactions to naming rules in Dynatrace.
Andrew
Regards,
Andrew M.
Andrew M.
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
20 Dec 2019 04:48 PM
Hi all,
I'm experiencing the same problem trying to clean UUID, I try in several ways but without good results. I tried as well creating a placeholder to clean the UUID but I think there's a bug in the "Processing steps" sections, in fact, if I place a replace rule with a leading and trailing delimiter, this is applied to all the text if the trailing delimiter is not present in the text to clean resulting in a quite impossible control of replacement. In my opinion the replace step should work as:
- Only "Leading delimiter" -> Replace everything after delimiter (if delimiter exist in text)
- Only "Trailing delimiter" -> Replace everything before delimiter (if delimiter exist in text)
- Leading & Trailing delimiter -> Replace everything inside delimiters (only if both delimiters exist in text)
Regards
Stefano
Options
- Mark as New
- Subscribe to RSS Feed
- Permalink
20 Jan 2020 10:21 AM
Hi Stefano G.,
I just tried to reproduce your mentioned scenario by doing the following steps in my demo environment, where I obtained the following results:
- I created a "replace" placeholder with a rule like "journeyId=" in the leading part (first match) and an empty trailing part (doesn't matter whether you pick first or last).
- In our preview section - a URL like http://www.test.com?journeyId=2667&someotherURLattribute=test would result in http://www.test.com?journeyId=&someotherURLattribute=test
Is this what you would expect / what you tried to achieve?
regards
Thomas
Reply
Featured Posts
